Use Chrome Tab Groups to Reduce the Size of the Haystack

Don’t you hate it when your Chrome browser has 1,000 open tabs and you can’t find / remember which one was what you were just looking at a few minutes ago? It’s easier to find a needle in a haystack!
One way to make tabs easier to find is to organize them using Chrome Tab Groups.
Chrome allows you to create these tab groups and move your tabs in and out of them. Here’s an example of some tab groups in action:

The colored tabs with AWS, Jenkins, Confluence, Github, and Jira were created by me, then I moved the appropriate browser tabs into each group. This has made finding tabs so much easier!
To get started, right click on any tab and choose Add Tab to Group → New Group:
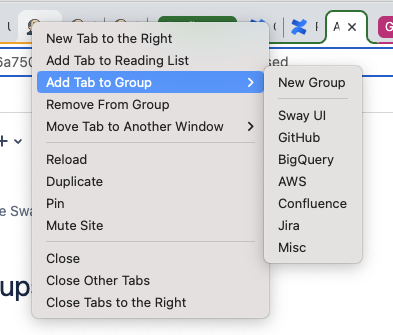
As you can see from the image, you can also use this method to move a tab to an existing group.
And, of course, you can drag and drop tabs into and out of existing tab groups.
Whew!



